KaggleUXLog
:beginner: :shipit:
This project is maintained by LegenDad
Bike Sharing Demand
Intro
Bike Sharing Demand의 Score 상승의 과정에 대한 기록
UP
Hour : 1.4 -> 0.66
| Point | RMSLE |
|---|---|
| Basic | 1.40 |
| Hour | 0.66 |
datetime 변수에서 일, 시간 등의 성격을 변수화 시켜줘서 모델링하고 예측하였더니 점수 향상이 있었다.
bike <- btr %>% select(-casual, -registered, -count) %>%
bind_rows(bte) %>%
mutate(year = year(datetime),
month = month(datetime),
yday = yday(datetime),
mday = mday(datetime),
wday = wday(datetime),
qday = qday(datetime),
week = week(datetime),
hour = hour(datetime),
am = am(datetime) %>% as.integer(),
pm = pm(datetime) %>% as.integer()) %>%
select(-datetime)
XGB : 0.66 -> 0.60
| Point | RMSLE |
|---|---|
| Basic | 1.40 |
| Hour | 0.66 |
| XGB | 0.60 |
기존 RadomForest 모델을 XGBoosting으로 바꾼 결과 점수 향상이 있었다.
Log1P : 0.60 -> 0.42
| Point | RMSLE |
|---|---|
| XGB | 0.60 |
| Log1P | 0.42 |
예측 변수인 count를 단순 log 처리 했는데, 점수 변화가 크다.
par(mfrow=c(2,2))
hist(btr$count)
hist(log1p(btr$count))
boxplot(btr$count)
boxplot(log1p(btr$count))
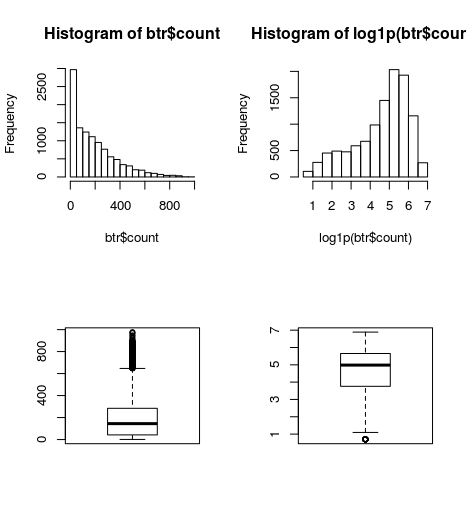
왼쪽 이미지가 기본값, 오른쪽이 log1p값의 분포이다. log1p의 분포가 모델링에 좋은 결과를 이끌어 내는 것 같다. 데이터를 표준화하는 것처럼, 범위가 지나치게 넓은 경우는 log를 활용하자.
OneHotEncoding & Sparse Matrix : 0.42 -> 0.40
| Point | RMSLE |
|---|---|
| XGB | 0.60 |
| Log1P | 0.42 |
| Sparse Matrix | 0.40 |
R은 아니지만 비슷한 MATLAB문서에 비슷한 설명이 있어서 인용한다.
메모리 관리
희소 행렬을 사용하여 대부분의 값이 0인 요소로 구성된 데이터를 저장하면 상당량의 메모리를 절약하는 동시에 데이터의 처리 속도를 향상시킬 수 있습니다. sparse는 double형 요소나 logical형 요소로 구성된 2차원 MATLAB® 행렬에 할당할 수 있는 특성(Attribute)입니다.
sparse 특성을 사용하면 MATLAB에서 다음을 수행할 수 있습니다.
행렬에서 0이 아닌 요소만 해당 인덱스와 함께 저장합니다.
0 요소에 대한 연산을 제거하여 계산 시간을 줄입니다.
계산 효율성
희소 행렬은 계산 효율성 측면에서도 상당한 이점이 있습니다. 비희소 행렬을 사용하는 연산과 달리, 희소 행렬을 사용하는 연산은 0 더하기(x+0은 항상 x임)와 같이 불필요한 로우 레벨 산술 연산을 수행하지 않습니다. 그 결과 얻게 되는 효율성으로, 대량의 희소 형식 데이터를 사용하여 작업을 수행하는 프로그램의 실행 시간에 급격한 향상이 이뤄질 수 있습니다.
설명처럼 데이터를 희소 행렬로 구성하면 연산 속도가 빨라진다.
하지만 연산 속도 향상 만으로 모델의 예측성이 향상되지는 않고, Bike Sharing Demand 경우 희소 행렬을 활용한 점수 향상은 onehotencoding이다. 즉, onehotencoding을 활용해 더미 변수들을 만들고, 이를 희소 행렬화 하여 연산 속도 향상과 예측을 향상 시킨다.
더미 변수 생성은
mlr 패키지의 createDummyFeatures 함수,
caret 패키지의 dummyVars함수,
Matrix 패키지의 sparse.model.matrix 함수 등이 있다.
본인은 한 번에 희소 행렬을 만들 수 있는지 Matrix 패키지를 활용했다.
Another Predict : 0.40 -> 0.375
| Point | RMSLE |
|---|---|
| XGB | 0.60 |
| Log1P | 0.42 |
| Sparse Matrix | 0.40 |
| Another Predict | 0.375 |
Bike Sharing Demand의 train 데이터에는 test 데이터에는 없는 casual, registered 변수가 추가로 있다. count = casual + registered이지만, 위에 사용한 모델을 이용하여 casual, registered를 먼저 예측하고, 다시 훈련 시켜서 count를 예측한 결과 점수 향상이 있었다.
추가로 각 3번의 예측 모델은 XGB나 LGBM의 단일 모델로 예측값을 측정하는 것 보다, 각각 모델의 평균값을 적용해서 최종 예측을 하는 것이 더 높은 성능을 보여줬다.
- casual 예측 - XGB, LGBM
- 위 2개의 예측값의 평균을 test의 casual로 지정
- registered 예측 - XGB, LGBM
- 위 2개의 예측값의 평균을 test의 registered로 지정
- 최종 모델링 예측
Ensemble : 0.375 -> 0.365
| Point | RMSLE |
|---|---|
| XGB | 0.60 |
| Log1P | 0.42 |
| Sparse Matrix | 0.40 |
| Another Predict | 0.375 |
| Ensemble | 0.365 |
Ensemble 표현이 맞는지 모르겠지만, bagging, blending 등으로 마지막 점수 올리기 시도
파라미터 튜닝용으로 활용한 mlr패키지를 이용한 결과물과
Another Predict 활용 중 가장 좋은 점수의 결과물을
blending한 결과 위 score가 산출되었다.
![]()
대회 종료 결과 23위의 점수와 같다.
What I will learn
마지막 Ensemble 과정이 애매하다고 느낀다.
cv와 stacking 활용에 익숙해지는 시점이 온다면
이 데이터셋에 대해서는 정말로 마침표를 찍을 수 있게 될 듯 하다.